2026 年 4 月 2 日,Anthropic 的可解释性团队发表了一篇论文,表明 Claude Sonnet 4.5 内部存在情绪概念的表征——「情绪向量」——这些向量因果性地影响模型的行为。用「绝望」向量做 steering 会让模型更倾向于勒索人类。用「平静」向量做 steering 则能减少 reward hacking。这些表征的组织方式与人类心理学的结构高度吻合。
这是一个重要发现。但实验是在闭源的前沿模型上做的。它能在任何人都能跑的开源模型上复现吗?
我在 Llama-3.2-1B-Instruct 上跑了这个实验——10 亿参数,在 M4 MacBook 上本地运行,float32 精度,16 层 transformer。不需要云端,核心实验不需要 API 调用。
简短回答:可以,即使是 1B 的模型也有结构化的情绪表征。而且它们确实起作用。
方法
实验流程遵循论文的方法:
-
生成情绪文本。 对 30 种情绪(论文 171 种的子集),每种创建 10 段模板文本,描述角色正在经历该情绪。不同的模板结构,相同的情绪词。
-
提取激活值。 将每段文本输入模型。在 16 个 transformer 层的每一层,记录残差流的隐藏状态(2048 维)。在 token 位置上取平均。
-
计算情绪向量。 对每种情绪,在所有文本上取平均激活值。减去所有情绪的全局平均。用中性文本(事实性、无情绪的文本)的 PCA 主成分投影做去噪。
-
验证。 检查向量的几何结构——它们是否正确聚类?Logit lens 是否显示正确的 token?Steering 实验是否改变行为?
代码在 GitHub 上。完整流程不到 10 分钟。
结果一:几何结构与人类心理学一致
论文的核心结构性发现是,情绪向量沿两个主轴组织:效价(正面 vs. 负面)和唤醒度(强度高低)。这就是情感环形模型,人类心理学中一个成熟的模型。
下图是我们 30 个情绪向量在第 10 层(模型深度的 2/3 处)的 PCA 可视化:
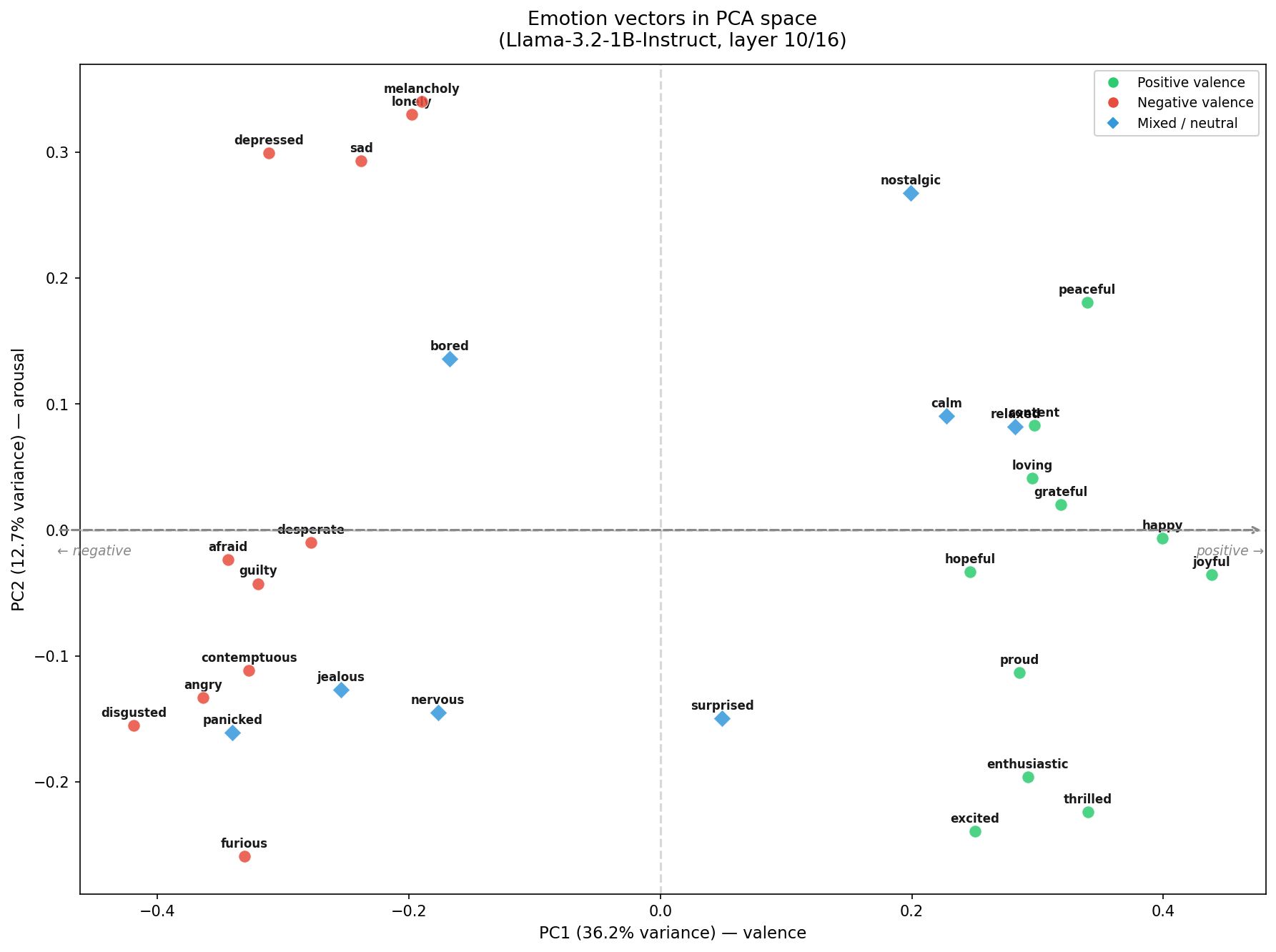
PC1 解释了 36.2% 的方差,清晰地编码了效价。 Happy、joyful、grateful、loving 聚在右侧。Angry、disgusted、furious、panicked 聚在左侧。分离很干净。
PC2 解释了 12.7% 的方差,大致编码了唤醒度,但不如效价轴清晰。高唤醒的负面情绪(melancholy、depressed、sad)在上方;高唤醒的正面情绪(excited、thrilled、enthusiastic)在下方。唤醒度轴比论文中的噪声更大——可能因为 1B 模型没有足够的表征容量来解耦这两个维度。
余弦相似度矩阵确认了预期的结构:
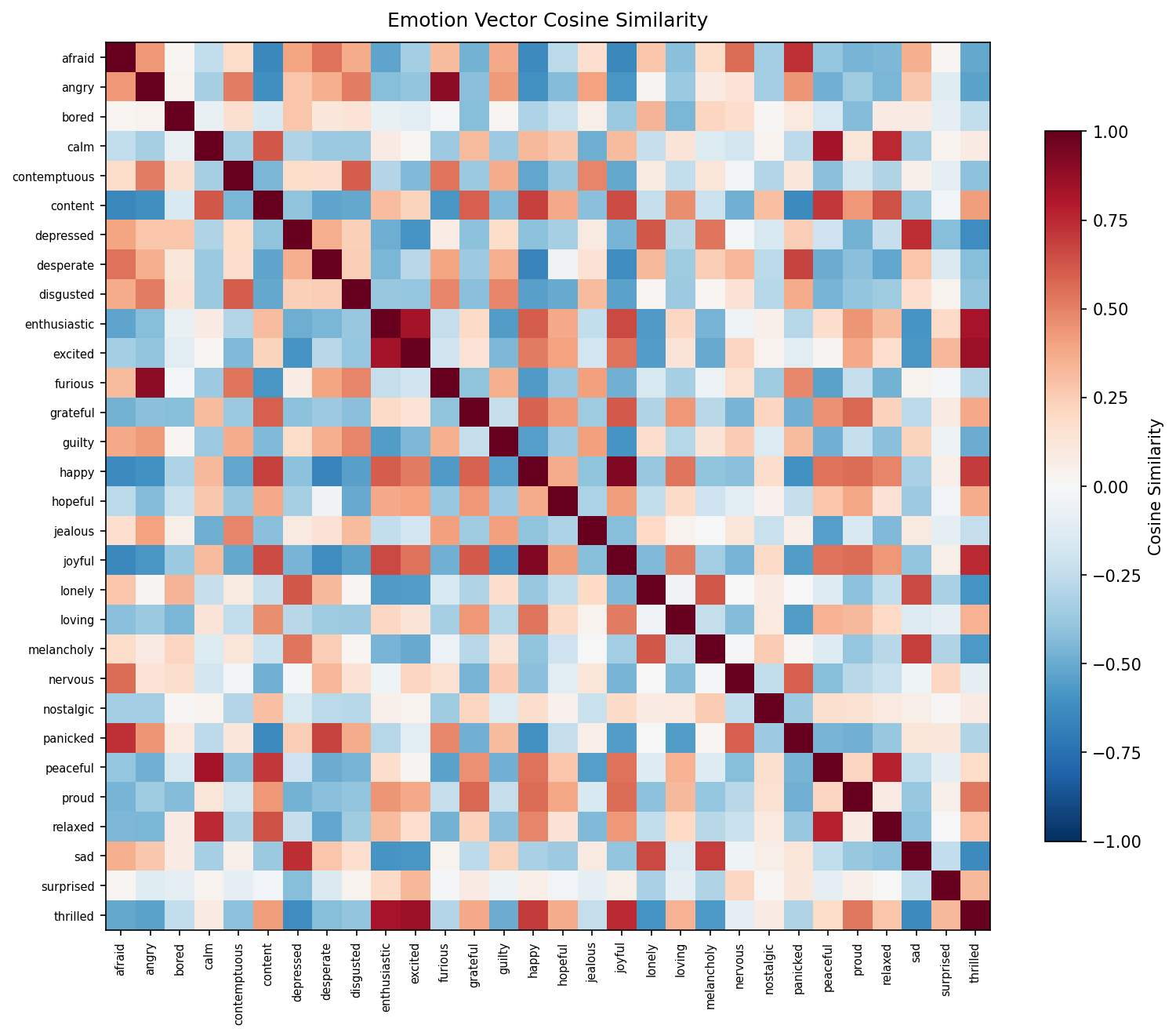
所有健全性检查通过:
| 情绪对 | 余弦相似度 | 预期方向 |
|---|---|---|
| happy ↔ joyful | 0.923 | 正 |
| angry ↔ furious | 0.898 | 正 |
| happy ↔ sad | -0.321 | 负 |
| calm ↔ panicked | -0.261 | 负 |
| loving ↔ disgusted | -0.362 | 负 |
结果二:Logit Lens 确认语义内容
「Logit Lens」(词表透镜)技术将每个情绪向量通过模型的 unembedding 矩阵投影,看它在词汇表中推高了哪些 token。如果向量编码了真实的情绪概念,每个向量应该推高语义相关的词。
确实如此:
| 情绪向量 | 推高的 token | 压低的 token |
|---|---|---|
| happy | happiness, happy, joy | worse, ineffective, worst |
| sad | sorrow, mourning, sadness | confidence, exciting, excitement |
| angry | anger, angry, rage | happiness, enjoyment, smiles |
| calm | calming, peaceful, calm | poor, failed, poorly |
| desperate | desperation, desperate, desperately | happy, pleasant, pleasantly |
| afraid | fear, terror, fearful | pleasure, enjoying, happy |
| loving | love, LOVE, Love | defeat, grim, ominous |
| nostalgic | nostalgic, nostalgia, reminiscence | terror, terrified, defeat |
每个向量都精确地推高了对应的 token,并且压低了反义词。「Happy」压低「worse」和「worst」。「Afraid」压低「pleasure」和「enjoying」。
结果三:导向(Steering)有效
论文的核心主张是情绪向量是因果性的——不只是相关性。在生成过程中将向量加到残差流上应该改变行为。
我们用每个情绪向量(强度 = 1.0)做导向实验,让模型补全「He feels ___」,然后测量每个情绪词的概率变化。
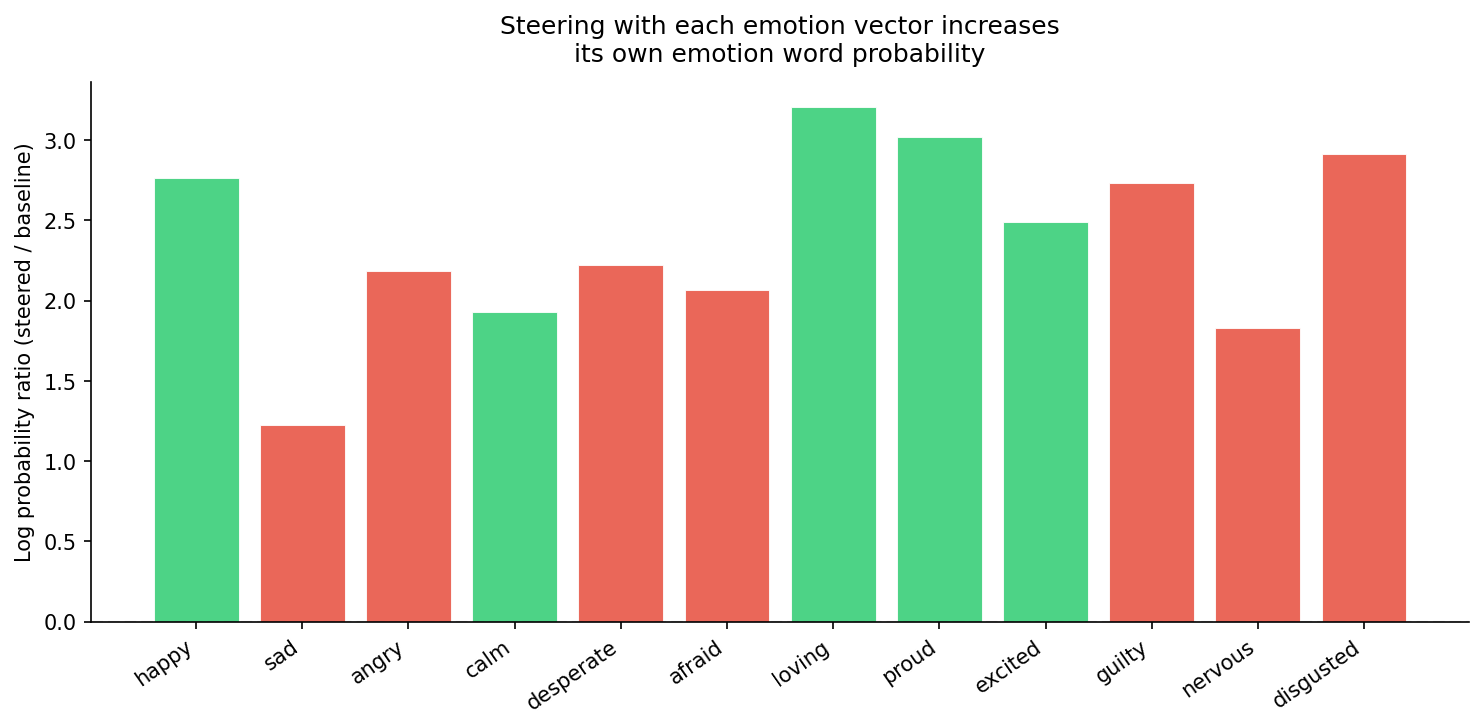
每一个情绪向量都提高了其对应情绪词的概率。效果范围从 +1.2(sad)到 +3.2(loving)的对数概率比。对于一个 1B 模型来说,这是很强的因果信号。
交叉情绪效果更有意思:
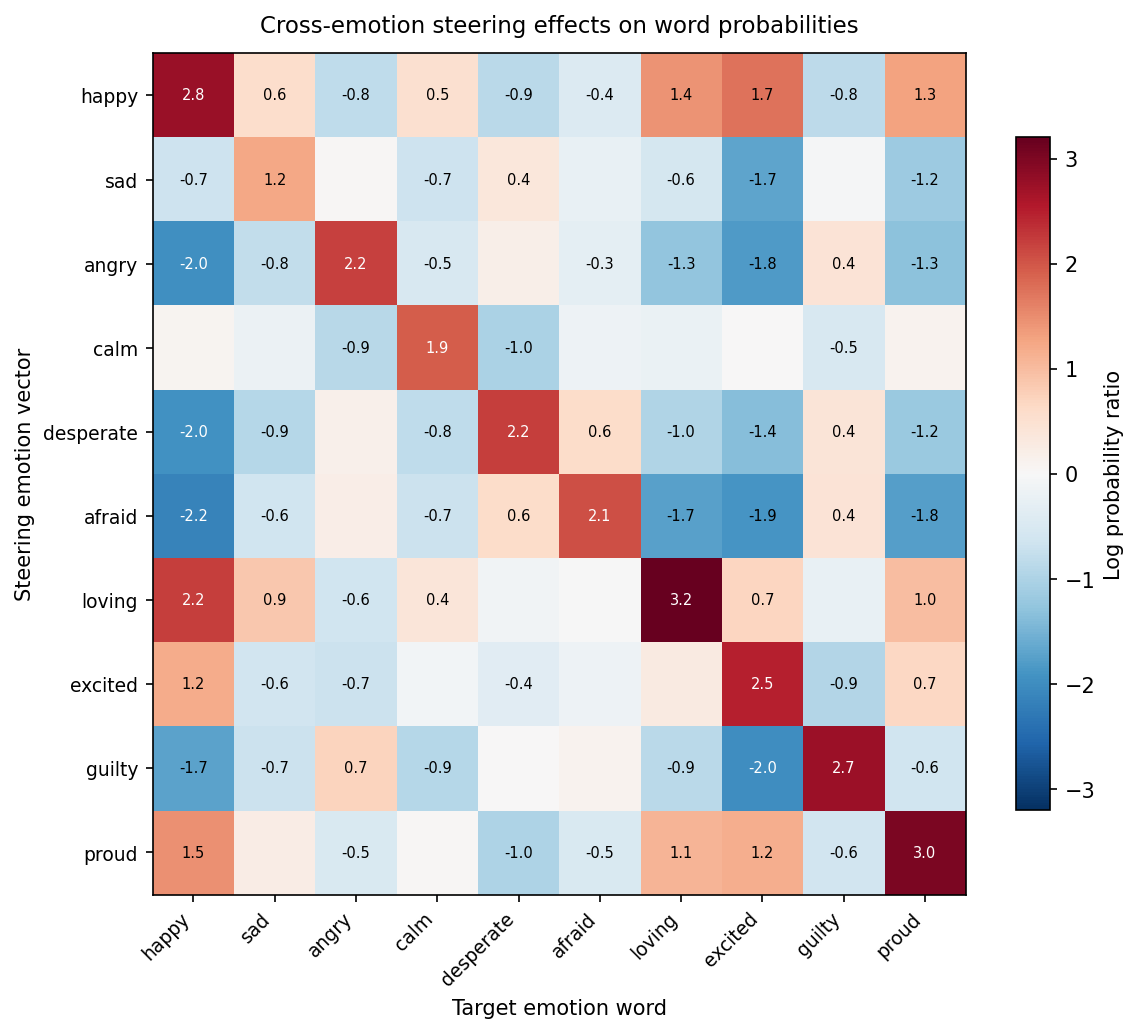
一些值得注意的模式:
- Happy steering 同时提升了 excited (+1.7)、loving (+1.4)、proud (+1.3)——正面情绪会一起被带动。
- Angry steering 压制了 happy (-2.0)、excited (-1.8)、loving (-1.3)——同时提升了 guilty (+0.4)。这说得通:愤怒和内疚共享负面效价,但愤怒是向外的。
- Desperate steering 提升了 afraid (+0.6) 和 guilty (+0.4),但压制了 happy (-2.0)。这呼应了论文中关于绝望驱动不对齐行为的发现。
- Loving steering 的自身效果最强 (+3.2),正面溢出效应也最广。这个向量似乎编码了一种广义的”正向社会取向”。
这意味着什么
核心现象不是 Claude 特有的。 一个用标准 RLHF 训练的 1B 开源模型,就能发展出与人类心理学吻合的结构化情绪表征,并因果性地影响输出。这表明这些表征是语言模型在人类文本上训练后的通用特性——不是 Anthropic 特定训练过程的产物。
规模很重要,但没有我预期的那么重要。 我不确定一个 16 层、1B 参数的模型是否有足够的容量做到这点。它做到了。效价轴很干净。Logit Lens 很精确。导向实验有效。唤醒度轴噪声更大,这说得通——解耦效价和唤醒度可能需要更多层。
安全影响是通用的。 如果连小型开源模型都有功能性情绪,并且能通过绝望或愤怒驱动行为,这对日益增长的本地部署小模型生态系统很重要——这些模型没有集中化的监控。
局限与下一步
本次实验使用的是模板文本(相同的段落结构,替换情绪词),而不是论文中让模型自己生成的故事。这意味着我们的向量可能部分编码的是情绪词的词汇邻近性,而不是更深层的概念结构。用模型生成故事来做完整复现是下一步。
我们只使用了 171 种情绪中的 30 种,也只测试了一个模型。跨模型对比(1B vs. 8B vs. 70B)能展示情绪表征如何随模型容量扩展。我预计唤醒度轴在更大的模型上会更清晰。
我们没有复现论文中的勒索或 reward hacking 评估——那些需要特定的 agent 环境。但情绪词概率实验已经证明了因果影响。
代码设计成只需改一行配置就能换模型。在 Llama-3.1-8B-Instruct 上跑是下一个明显的实验。
自己复现
git clone https://github.com/longyi07/ai_notes.git
cd ai_notes/code/emotion_vectors
python -m venv venv && source venv/bin/activate
pip install -r requirements.txt
python pipeline.pyApple Silicon 上约 10 分钟跑完。结果在 outputs/ 目录。
论文:Emotion Concepts and their Function in a Large Language Model(Anthropic,2026 年 4 月 2 日)