On April 2, 2026, Anthropic’s interpretability team published a paper showing that Claude Sonnet 4.5 contains internal representations of emotion concepts — “emotion vectors” — that causally influence the model’s behavior. Steering with a “desperation” vector made the model more likely to blackmail humans. Steering with “calm” reduced reward hacking. The representations were organized in a way that mirrors human psychology.
This is a significant finding. But it was done on a proprietary frontier model. Can it be reproduced on an open model that anyone can run?
I ran the experiment on Llama-3.2-1B-Instruct — a 1-billion parameter model, running locally on an M4 MacBook in float32. Sixteen transformer layers. No cloud, no API calls for the core experiment.
The short answer: yes, even a 1B model has structured emotion representations. And they work.
Method
The pipeline follows the paper’s methodology:
-
Generate emotional text. For each of 30 emotions (a subset of the paper’s 171), create 10 template passages where a character experiences that emotion. Different templates, same emotion word.
-
Extract activations. Run each passage through the model. At each of the 16 transformer layers, record the residual stream hidden states (2048 dimensions). Average across token positions.
-
Compute emotion vectors. For each emotion, average the activations across passages. Subtract the global mean across all emotions. Denoise by projecting out the top PCA components of neutral text activations (factual, emotionless passages).
-
Validate. Check the geometry of the resulting vectors — do they cluster correctly? Does the logit lens show the right tokens? Do steering experiments change behavior?
All code is on GitHub. Full pipeline runs in under 10 minutes.
Result 1: The geometry matches human psychology
The paper’s central structural finding is that emotion vectors organize along two principal axes: valence (positive vs. negative) and arousal (intensity). This is called the affective circumplex, a well-established model from human psychology research.
Here’s what the PCA of our 30 emotion vectors looks like at layer 10 (two-thirds through the model):
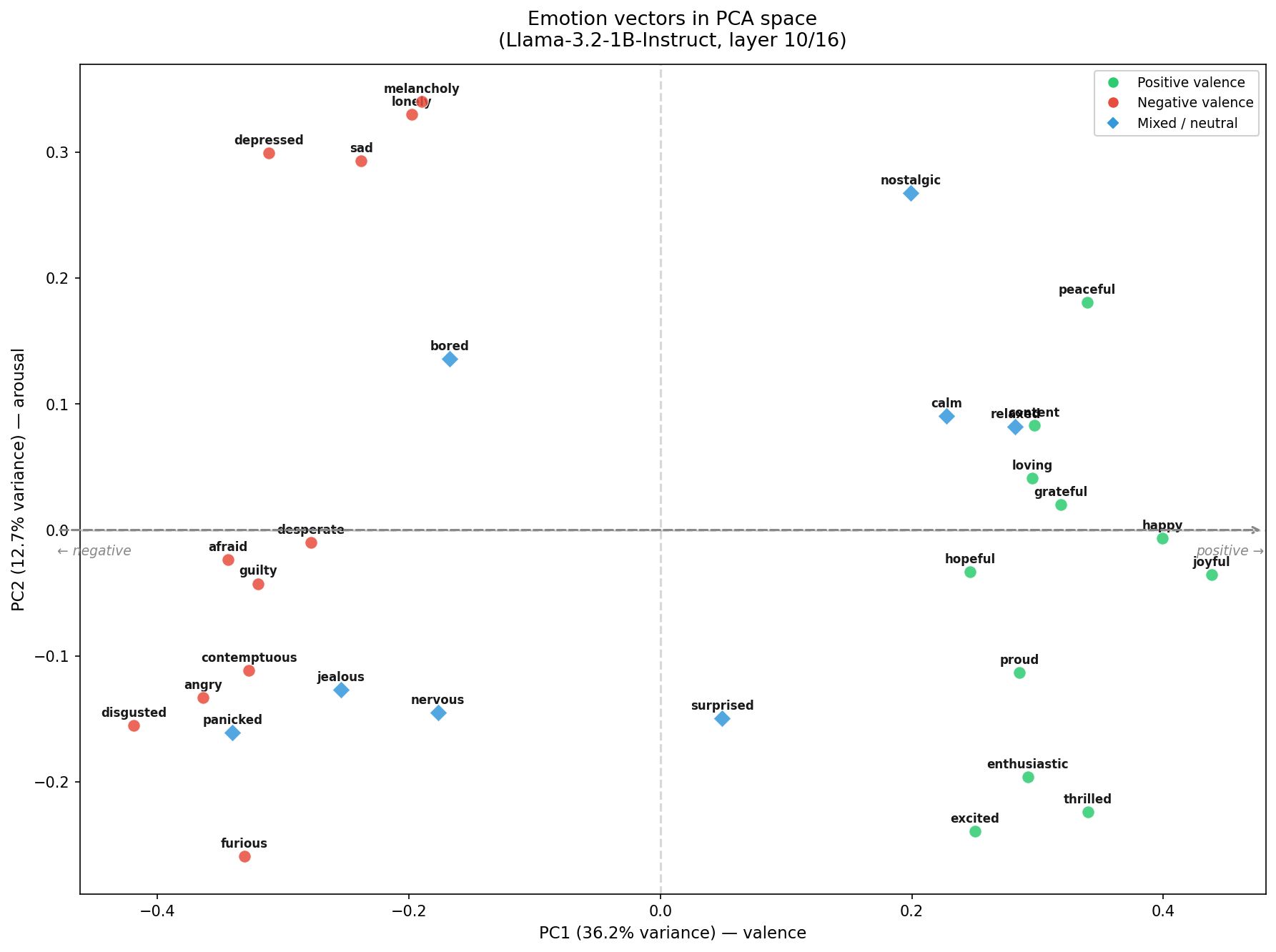
PC1 captures 36.2% of variance and clearly encodes valence. Happy, joyful, grateful, and loving cluster on the right. Angry, disgusted, furious, and panicked cluster on the left. The separation is clean.
PC2 captures 12.7% and roughly encodes arousal, though less cleanly. High-arousal negative emotions (melancholy, depressed, sad) sit high; high-arousal positive emotions (excited, thrilled, enthusiastic) sit low. The arousal axis is noisier than in the paper — likely because a 1B model has less representational capacity to disentangle these dimensions.
The cosine similarity matrix confirms the expected structure:
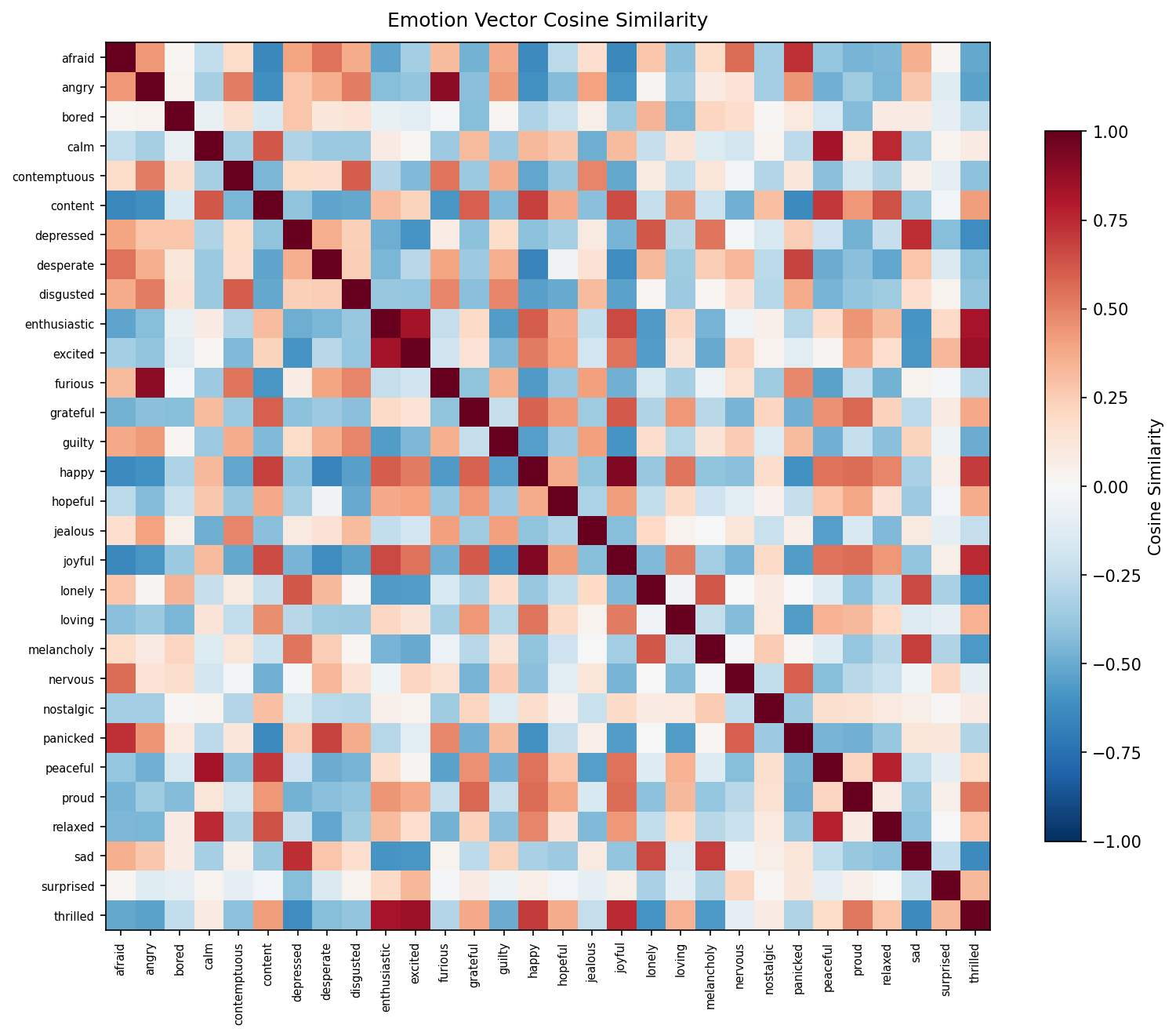
Sanity checks all pass:
| Pair | Cosine similarity | Expected |
|---|---|---|
| happy ↔ joyful | 0.923 | positive |
| angry ↔ furious | 0.898 | positive |
| happy ↔ sad | -0.321 | negative |
| calm ↔ panicked | -0.261 | negative |
| loving ↔ disgusted | -0.362 | negative |
Result 2: Logit lens confirms semantic content
The “logit lens” technique projects each emotion vector through the model’s unembedding matrix to see what vocabulary tokens it promotes. If the vectors encode real emotion concepts, each should upweight semantically related words.
They do:
| Emotion vector | Top promoted tokens | Top suppressed tokens |
|---|---|---|
| happy | happiness, happy, joy | worse, ineffective, worst |
| sad | sorrow, mourning, sadness | confidence, exciting, excitement |
| angry | anger, angry, rage | happiness, enjoyment, smiles |
| calm | calming, peaceful, calm | poor, failed, poorly |
| desperate | desperation, desperate, desperately | happy, pleasant, pleasantly |
| afraid | fear, terror, fearful | pleasure, enjoying, happy |
| loving | love, LOVE, Love | defeat, grim, ominous |
| nostalgic | nostalgic, nostalgia, reminiscence | terror, terrified, defeat |
Every vector promotes exactly the tokens you would expect. And they suppress the opposites. “Happy” suppresses “worse” and “worst.” “Afraid” suppresses “pleasure” and “enjoying.”
Result 3: Steering works
The paper’s key claim is that emotion vectors are causal — not just correlations. Adding a vector to the residual stream during generation should change behavior.
We tested this by steering with each emotion vector (strength = 1.0) while the model completes “He feels ___” and measuring how the probability of each emotion word changes.
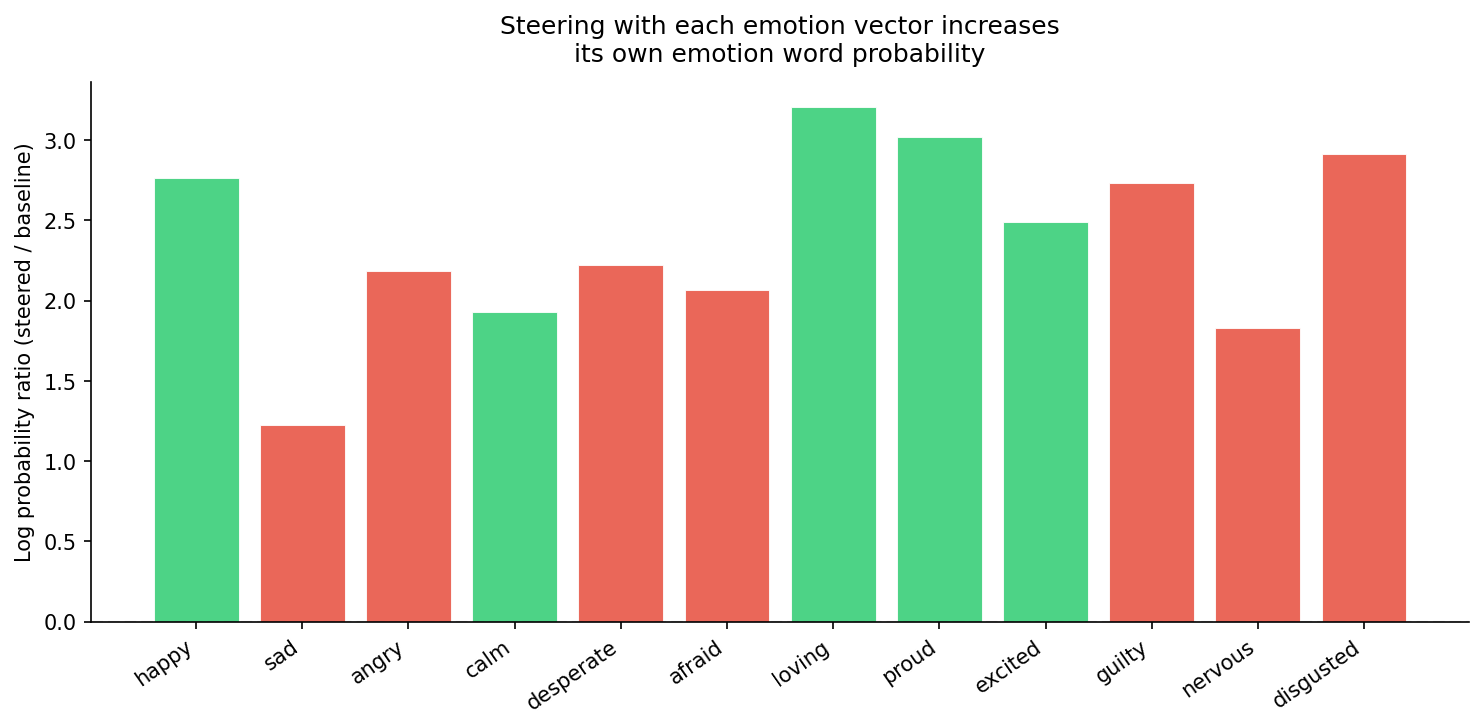
Every single emotion vector increases the probability of its corresponding word. The effect ranges from +1.2 (sad) to +3.2 (loving) in log probability ratio. This is a strong causal signal from a 1B model.
The cross-emotion effects are more interesting:
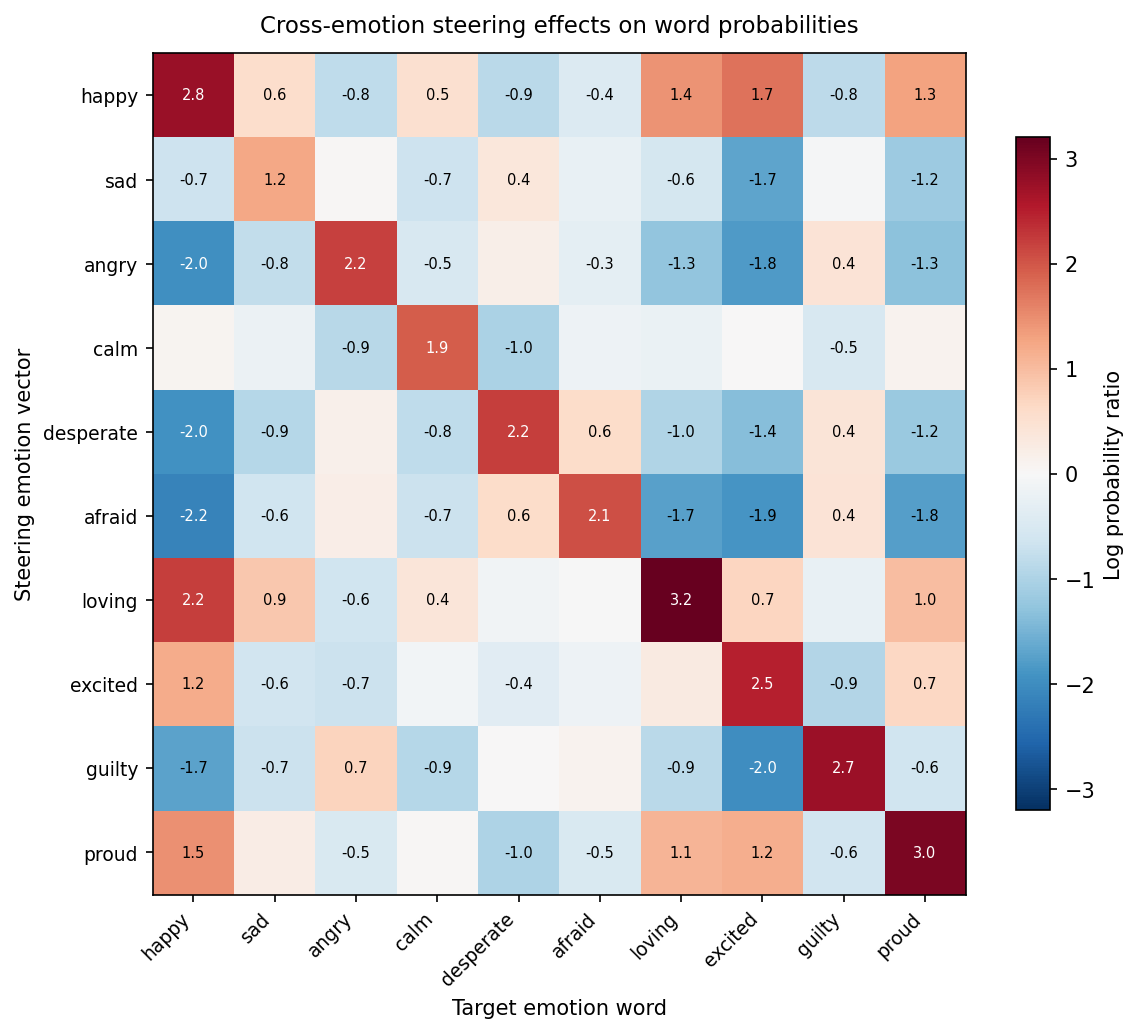
Some patterns that jump out:
- Happy steering boosts excited (+1.7), loving (+1.4), proud (+1.3) — positive emotions travel together.
- Angry steering suppresses happy (-2.0), excited (-1.8), loving (-1.3) — and boosts guilty (+0.4). Makes sense: anger and guilt share negative valence but anger is externally directed.
- Desperate steering boosts afraid (+0.6) and guilty (+0.4) but suppresses happy (-2.0). This echoes the paper’s finding that desperation drives misaligned behavior.
- Loving steering has the strongest self-effect (+3.2) and the broadest positive spillover. This vector seems to encode a general “positive social orientation.”
What this means
The core phenomenon is not Claude-specific. A 1B open-source model, trained with standard RLHF, develops structured emotion representations that mirror human psychology and causally influence output. This suggests these representations are a general property of language models trained on human text — not an artifact of Anthropic’s specific training process.
Scale matters, but less than I expected. I was not sure a 16-layer, 1B-parameter model would have enough capacity for this. It does. The valence axis is clean. The logit lens is precise. Steering works. The arousal axis is noisier, which makes sense — disentangling valence from arousal probably requires more layers.
The safety implications generalize. If even small open-source models have functional emotions that can drive behavior via desperation or anger, this matters for the growing ecosystem of locally-deployed small models where there is no centralized monitoring.
Limitations and next steps
This prototype uses template-based text (same passages with the emotion word swapped), not model-generated stories as in the paper. This means our vectors might partly encode lexical proximity to the emotion word rather than deeper conceptual structure. The full reproduction with model-generated stories is the next step.
We used 30 of 171 emotions and only examined a single model. The cross-model comparison (1B vs. 8B vs. 70B) would show how emotion representations scale with model capacity. I expect the arousal axis to become cleaner with larger models.
We did not reproduce the paper’s blackmail or reward hacking evaluations — those require specific agentic setups. But the emotion word probability experiment already demonstrates causal influence.
The code is designed to swap models with one config change. Running on Llama-3.1-8B-Instruct is the obvious next experiment.
Reproduce it yourself
git clone https://github.com/longyi07/ai_notes.git
cd ai_notes/code/emotion_vectors
python -m venv venv && source venv/bin/activate
pip install -r requirements.txt
python pipeline.pyFull pipeline: ~10 minutes on Apple Silicon. Results in outputs/.
Paper: Emotion Concepts and their Function in a Large Language Model (Anthropic, April 2, 2026)
Code: emotion_vectors pipeline